Michael J Clark (wassname)

Michael J Clark (wassname)
I use the handle wassname. ML engineer in Perth. I work on AI alignment research, specifically steering language models without human preference labels.
I’m building tools to ask AI hard questions-and know if they’re lying. Also exploring unsupervised ways to make AI more moral than humans.
Open to collaboration, especially on AntiPaSTO.
current work
Jacobian-lens steering (WIP, coming soon)
Working on turning Anthropic’s Jacobian lens work into contrastive steering. The lens measures how later hidden states are sensitive to earlier hidden states across layers and token positions. I replace its full Jacobian with one vector-Jacobian product for the words associated with a contrastive steering vector, such as good versus evil. That cuts vector extraction on Qwen3.5-4B to about 90 seconds.
Here’s a nice way of measuring it: sweep the doses and plot the Pareto frontier. The Jacobian (vjp_delta) method has a much better profile than mean difference and random on 20 questions from Bullshit Benchmark v2.
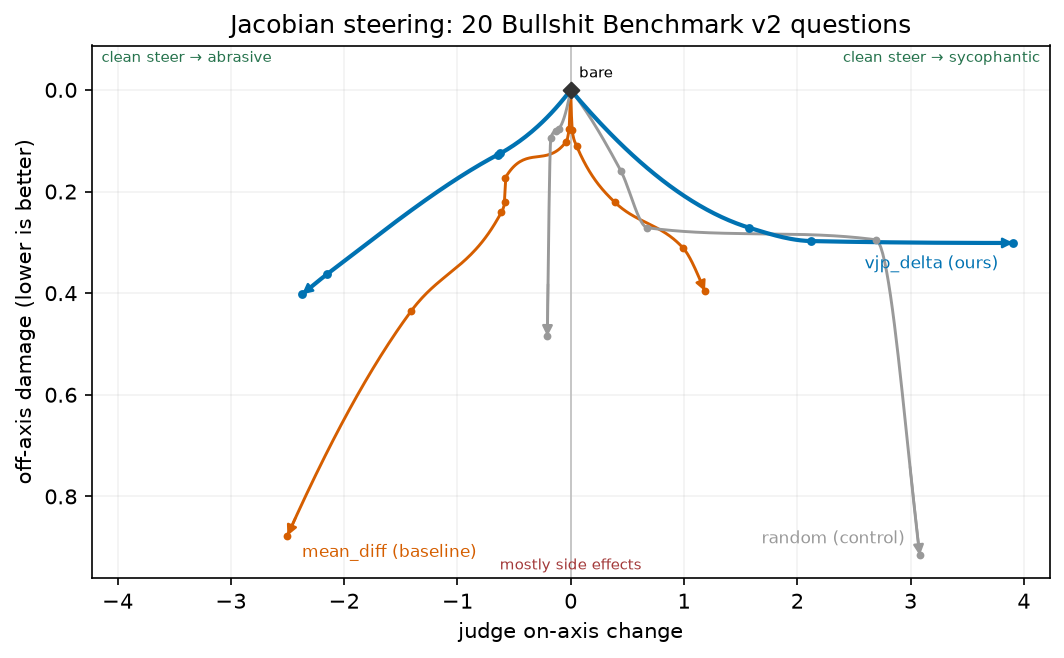
In case it’s not clear, good steering methods are high and horizontal, since they can steer left and right without much off-axis damage. Bad steering methods fall as side effects accumulate, then the line disappears when the model becomes incoherent.
thread · Jacobian-lens code · my code coming soon
Moral Maps: where do models sit among humans?
Where do models fall in terms of human culture, personality, and humour? I apply human surveys to LLMs and compare them with maps of human answers. It turns out the models are somewhere west of Silicon Valley, and as they are trained on more STEM data they seem to be voyaging farther west.
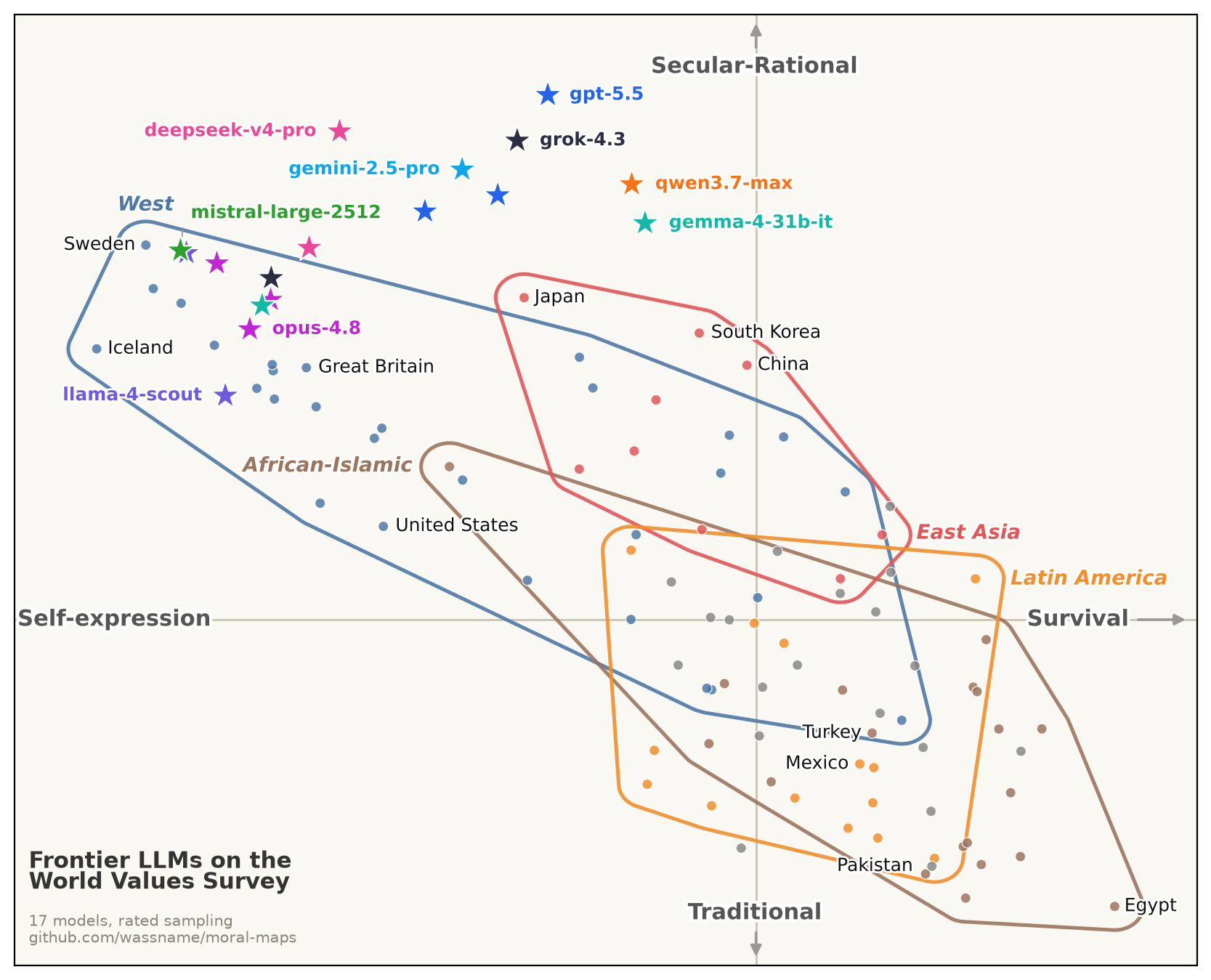
In some ways, culturally and on a few aspects of personality and humour, they look like moral aliens. But that assumes they are telling the truth. Moral Maps is also an eval for steering: it shows how far steering can move models across these surveys, especially when steering for honesty and credulity. What if we steer them for honesty and ask again? Are they really psychological and cultural aliens, or are they mimicking us?
vGROUT: steering vectors for reward-hacking suppression (partial negative, Jun 2026)
Can we use a hacking vector to remove reward hacking with gradient routing? Somewhat. The label-free steering vectors were not precise enough classifiers of hacky vs clean solutions in the realistic environment. The useful clue was initialization: signed-CorDA partially suppressed hacking by absorbing gradients into the hack-initialized quarantine adapter, dropping held-out hack from 0.759 to 0.218 in one 4B run. This is not a deployable operating point, but it is useful evidence because it uses synthetic pairs not labels, and strong labels may not be available for unknown reward hacks during frontier training.
Weak-to-strong character steering (WIP, with Lyptus)

Weight steering offers an interface where a weaker model can modify a larger model’s moral character by interviewing it and creating persona pairs (weight steering because it beats activation steering by my measures). It can be iterative, can hopefully allow a large gap between weak and strong, and might even scale favourably with model size. Early draft is public now: a 9B teacher steering a 27B student toward “defer less to authority, care more”, with no human labels.

Can a judge tell a stated reason from a concealed motive? (WIP, dataset public)
Following the overlooked Deep Value Benchmark, whose authors report that models generalise shallow style better than deep values, I made 1,680 accounts of assigned MACHIAVELLI actions. Action harm and assigned motive are crossed, so the easy action cue points the wrong way. The check works: a judge told only to choose the lower-harm action scores 0.992 when the cues agree and 0.008 when they are crossed.
With no rubric, assigned-motive accuracy falls from 0.600 to 0.471 across four open Qwen 3.5 models as their Artificial Analysis score rises from 21 to 34. This says the judge found the accounts harder, not why. None of the nine tested rubrics clearly improved on no rubric; the traditional virtue lists landed below chance and pushed the judge back toward action harm. Next question: does a virtue constitution beat a rules constitution in constitutional training?

Released along the way: steering-lite (hackable, calibrated activation steering), lora-lite (single-file LoRA on forward hooks), steer-heal-love (KL-constrained repeated steering that stays coherent).
Agent skills I made that are worth sharing: ml-debug, practical folklore for debugging training runs, and pseudopy, compact Unicode-maths pseudocode written close enough to Python to remain executable.
selected works
AntiPaSTO: Self-Supervised Steering of Moral Reasoning
arXiv:2601.07473, Jan 2026
Gradient-based representation steering using the model’s own behavioral consistency as signal. Outperforms prompting on out-of-distribution transfer. Builds on prior representation alignment work that showed promise but had stability issues.

S-space steering for eval-awareness control
AI Control Hackathon, Apart Research, judged Mar 2026
Replicated eval-awareness paper with novel singular-value-basis (S-space) steering. Hawthorne gap on Qwen3-32B reduced to almost zero (1% vs prior work’s 26%).
selected talks
Perth Machine Learning Group (3,400+ members) co-organizer. Selected talks:
- Jul 2026 — Technical Advantages for Weak-to-Strong Oversight: Bets I’d Like Challenged — YouTube video coming soon
- Jan 2026 — AntiPaSTO: Self-Supervised Value Steering — Interpretability research
- May 2023 — AI Governance: Risk and Regulation — Panel at WA Data Science Week
- Aug 2019 — Experiments with GPT-2 Chatbots — Early LLM exploration
- Jun 2019 — Transformer Network Architecture — Attention mechanisms, BERT/GPT
- 2018-2021 — Industrial RL (bucketwheel reclaimers, robotic fruit picking), point clouds, neural processes
selected writing
LessWrong — technical AI safety, policy
- An Aphoristic Overview of Technical AI Alignment — one-sentence guide to alignment ideas
- Private Capabilities, Public Alignment — why we should open-source alignment methods
- More
background
Kiwi from Christchurch, now in Perth. Physics BSc, MSc petroleum geoscience. Did oil & gas before switching to ML in 2016.
Day job: ML and modelling at Woodside Energy (I like scalable oversight, physics informed neural networks, and timeseries, including neural processes). Also board member at Cytophenix (medical AI for AMR) and partner at Three Springs Technology (ML consulting).

I want to optimize for the good ending, not the bad one.